Ученые из Калифорнийского университета в Сан-Франциско создали нейропротез, который преобразует активность мозга в речь почти без задержки. Эта технология дает надежду людям с тяжелыми формами паралича, например, после инсульта ствола мозга, которые полностью утратили способность говорить. В исследовании, опубликованном в журнале Nature Neuroscience, участвовала 47-летняя женщина с анартрией – состоянием, при котором человек не может говорить из-за паралича речевых мышц. И благодаря имплантированным электродам ей вернули эту возможность.
Credit: Kaylo T. Littlejohn et al. / Nature Neuroscience 2025
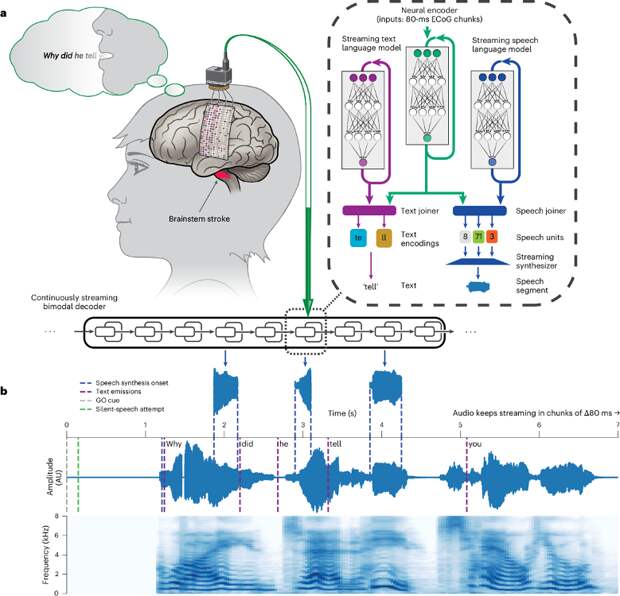
Мозговая активность пациентки записывалась через имплантированную сеть из 253 электродов, покрывающих речевую сенсомоторную кору. Эти электроды фиксировали высокочастотные гамма-волны и низкочастотные сигналы, связанные с попытками артикуляции, даже когда она просто «воображала» слова, не двигая ртом.
Для декодирования сигналов использовалась рекуррентная нейронная сеть с трансдьюсером (RNN-T), изначально разработанная для распознавания речи. Модель обрабатывала данные блоками по 80 мс, что позволяло синтезировать речь в реальном времени, а не ждать окончания фразы. Обучение проводилось на 23 тысячах попыток «беззвучной речи» с использованием 1024 слов. Чтобы вернуть пациентке ее естественный голос, ученые применили короткую аудиозапись, сделанную до инсульта, и синтезатор на основе генеративно-состязательной сети, который преобразовывал декодированные фонемы в ее собственную речь.
Система показала впечатляющие результаты: скорость декодирования достигла 47.5 слов в минуту для большого словаря и 90.9 слов – для набора из 50 повседневных фраз, что в 1.5–2 раза быстрее предыдущих аналогов. Задержка между мысленной артикуляцией и синтезом речи составила в среднем 1.12 секунды, тогда как ее текущий ассистивный прибор требовал 23 секунды на формирование фразы. Правда, точность варьировалась: ошибка на уровне фонем (PER) была 10.8% для простых фраз и 45.3% – для сложных предложений. Текст декодировался немного точнее – 7.58% и 23.9% ошибок.
В оффлайн-режиме система работала до 6 минут без перерыва, автоматически определяя моменты «речи» и «тишины» с минимальными ложными срабатываниями (3 из 100 случаев). Технология также адаптировалась к другим интерфейсам, включая микроэлектродные массивы у пациентов с параличом и электромиографию речевых мышц у здоровых людей.
Ключевым преимуществом стала возможность обучения без голоса – многие аналоги требуют попыток озвучивания, что невозможно при анартрии. Низкая задержка критична для естественного диалога – даже паузы в 2-3 секунды нарушают коммуникацию. Персонализация голоса, как отметили исследователи, помогает сохранить идентичность пациента, что психологически крайне важно. Участница исследования сообщила, что чувствует больший контроль над синтезатором, чем над текстовым интерфейсом: «Для нее это не просто инструмент – это возможность снова «быть услышанной» в прямом смысле», – пояснил руководитель проекта Эдвард Чанг.
Однако технология пока далека от совершенства. Точность синтеза уступает текстовым декодерам, а испытания проведены только на одном участнике. Ученые уверены, что улучшение разрешения электродов и объемов данных повысит эффективность. В будущем система может стать основой для имплантов, работающих годами, и интегрироваться с повседневными гаджетами. Как подчеркивают авторы, цель – дать людям с параличом не просто «голос», а возможность вести живой, эмоциональный диалог, сохраняя естественность общения.
Текст: Анна Хоружая
A streaming brain-to-voice neuroprosthesis to restore naturalistic communication by Kaylo T. Littlejohn et al. in Nature Neuroscience. Published March 2025
Свежие комментарии